Предварительный анализ медицинских данных в пространстве меньшей размерности. Метод главных компонент
Во многих задачах обработки и анализа биомедицинских данных исходное число р рассматриваемых, т.е. измеряемых на исследуемых объектах, признаков довольно велико. Для визуализации картины, простоты интерпретации и упрощения расчетов очень часто необходимо представить каждое из наблюдений в виде набора чисел, состоящего из существенно меньшего, чем р, числа признаков. При этом оставшиеся признаки могут либо выбираться из числа исходных, либо определяться по какому-либо правилу по совокупности исходных признаков, например, как линейные комбинации последних.
Главные компоненты представляют собой новое множество исследуемых признаков y(1), y(2), … , y(p) каждый из которых получен в результате некоторой линейной комбинации непосредственно измеренных на объектах исходных признаков x(1), x(2), … , x(p). Полученные в результате такого преобразования новые признаки y(1), y(2), … , y(p) могут обладать рядом удобных статистических свойств, например, быть упорядоченными по степени рассеяния в изучаемой совокупности объектов: первый признак обладает наибольшей степенью рассеяния, т. е. наибольшей дисперсией, второй — меньшей, и т. д.
Рассмотрим метод вычисления главных компонент1. Будем предполагать, что исследуемые наблюдения Х1, Х2, …. Хn извлечены из некоторой р мерной генеральной совокупности, определяемой соответствующей вероятностной мерой. Из всех характеристик исследуемой совокупности данных существенное значение имеет ковариационная матрица Σ = |σij|, где
σij = M (x(i) – а(i))(x(j) — а(j)), i, j = 1, 2…..р. (1.5)
Здесь а(i)— компоненты вектора а средних значений признаков x(i). Будем считать, что в (1.5) а = 0. Этого всегда можно добиться, рассматривая в качестве исходных признаков x(1), x(2), … , x(p) не сами
измерения, а их отклонения от выборочных средних значений.
Первой главной компонентой исследуемой совокупности наблюдений называется такая нормированная линейная комбинация р исходных признаков x(1), x(2), … , x(p):
у(1)=l11x(1) + l12x(2) + … + l1рx(p)=L1TХ
(L1T = |l11 l12 … l1р|, l211 + l212+ … + l21p = 1), которая среди всех прочих нормированных линейных комбинаций обладает наибольшей дисперсией.
Вообще, i-й главной компонентой исследуемой генеральной совокупности (i = 1,3, …,р) называют такую нормированную линейную комбинацию р исходных признаков x(1), x(2), … , x(p)
у(i)=li1x(1) + li2x(2) + … + liрx(p)=LiTХ,
которая среди всех прочих линейных нормированных (l2i1 + l2i2+ … + l2ip = 1) комбинаций, некоррелированных со всеми предшествующими главными компонентами y(1), … , y(i-1) (т.е. cov(y(i), y(j)) = М(y(i), y(j)) = 0 для j < i), обладает наибольшей дисперсией.
Из определения следует, что, во-первых, главные компоненты y(1), y(2), … , y(p) пронумерованы в порядке убывания их дисперсий, т.е. Dy(1) ≥Dy(2)≥ … ≥ Dy(p) , где
Dy(i) = M(LiTX)2 = M(LiTXXTLi)= LiTΣLi, (1.6)
и, во-вторых, вектор Li, определяющий переход от x(1), x(2), … , x(p) к у(i), является i-м собственным вектором ковариационной матрицы Σ, т.е. его компоненты li1,li2, …, liр определяются как нормированное  решение системы уравнений
решение системы уравнений
(Σ-λiI)Li =0. (1.7)
Эта система линейных однородных уравнений имеет ненулевое решение только в том случае, когда ее определитель равен нулю, т.е.
|Σ-λI|=0, (1.8)
где | • | означает определитель матрицы, λ — неизвестное число, I единичная матрица.
Выражение (1.8), в котором определитель матрицы (Σ-λI) является многочленом степени р относительно λ, называют характеристическим уравнением, а его корни λi, i = 1,2…..р собственными значениями матрицы Σ.
Каждому собственному значению λi, определяемому из (1.8), соответствует свой собственный вектор Li, матрицы Σ. Составляющие этого вектора li1,li2, …, liр для конкретного значения λi, могут быть
найдены путем решения системы уравнений (1.7).
Из сопоставления (1.6)-(1.8) следует, что
Dу(i) = LiTΣLi = LiTλiILi = λi.
Таким образом, ковариационная матрица ΣY главных компонент y(1), y(2), … , y(p) будет иметь вид диагональной матрицы
![\boldsymbol{\Sigma}_{Y}=\left[\begin{array}{ccccc}{\lambda_{1}} & {0} & {0} & {\ldots} & {0} \\ {0} & {\lambda_{2}} & {0} & {\ldots} & {0} \\ {\ldots} & {\ldots} & {\ldots} & {\ldots} & {\ldots} \\ {0} & {0} & {0} & {\ldots} & {\lambda_{p}}\end{array}\right]](https://cmi.to/wp-content/ql-cache/quicklatex.com-3c0eefa826cf7c4541c06ad2d8a5bdcf_l3.png "Rendered by QuickLaTeX.com")
Учитывая, что преобразование, с помощью которого осуществляется переход от исходных компонент X к главным компонентам Y (Y = LX), является ортогональным, исходные переменные x(1), x(2), … , x(p) можно выразить через главные компоненты
x(i)=l1iy(1) + l2iy(2) + … + lрiy(p)
(в матричной записи X = L T Y).
Несмотря на то, что для р исходных признаков получено р главных компонент, вклад большей их части в суммарную дисперсию оказывается небольшим. Поэтому, исключив из рассмотрения те компоненты, вклад которых мал, можно существенно сократить размерность исследуемого признакового пространства.
Ортогональное преобразование Y = LX оставляет инвариантной обобщенную дисперсию, а также сумму дисперсий компонент исходного вектора X и, как следствие, суммарная дисперсия (Dy(1) +Dy(2)+ … + Dy(p) ) главных компонент, равная сумме собственных чисел (λ1 + λ2+ … + λр), также равна сумме дисперсий (Dx(1) +Dx(2)+ … + Dx(p) ) исходных признаков2. Па этом основании принимается решение о том, сколько последних главных компонент можно исключить из последующего рассмотрения. Для этого проводится анализ изменения относительной доли дисперсии
 (1.9)
(1.9)
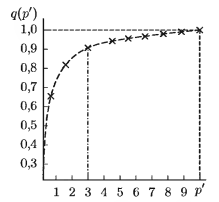
(1≤ p’ ≤ p), вносимой первыми p’ главными компонентами, и определяется число компонент, которое целесообразно сохранить. Так, для примера кривой q (p’) изображенной на рис. , очевидно возможно сокращение размерности пространства с р = 10 до р = 3. так как вклад семи последних главных компонент в суммарное рассеяние составляет не более 10 %.
Анализируя лишь p’ = 3 первых, т.е. наиболее весомых главных компонент, можно объяснить основную долю, а именно, 90 % суммарной дисперсии и выявить особенности рассеяния или группировки наблюдений.
Такой анализ главных компонент целесообразен, если величины x(1), x(2), … , x(p) являющиеся составляющими вектора X, имеют одинаковую размерность. В случае, если признаки x(1), x(2), … , x(p) измеряются в различных физических единицах, на этапе предобработки необходимо перейти к безразмерным признакам x*(i) например, с помощью нормирующего преобразования вида
 ,
,
где σij соответствует (1.5), а затем вычислять главные компоненты относительно этих признаков x*(1), … , x*(p) и их ковариационной матрицы.
Пример. Исходные данные представляют собой результат описания множества реализаций электрокардиограмм ЭКГ (ритмограмм) набором признаков x(1), x(23), x(3), x(4), x(5). Эти признаки получены
в процессе вычисления и анализа параметров энтропии Колмогорова, которая отражает степень сложности (хаотичности) сигналов. Выборка данных включает несколько классов ЭКГ: мерцательная аритмия (МА), нормальный ритм (IIP), частая экстрасистолия (ЧЭ). Каждый класс представлен 25 объектами.
Требуется перейти от исходных признаков к главным компонентам, оценить долю дисперсии, которая обеспечивается первыми двумя главными компонентами (y(1), y(2)) , и отобразить объекты в пространстве новых признаков.
По данным измерений в соответствии с формулой (1.5) определена выборочная ковариационная матрица Σ — |σij|
![\left[\begin{array}{rrrrr}{0,327} & {0,177} & {-4,359 \cdot 10^{-4}} & {-0,061} & {-0,085} \\ {0,177} & {0,112} & {0,018} & {-0,023} & {-0,052} \\ {-4,359 \cdot 10^{-4}} & {0,018} & {0,026} & {0,015} & {-1,636 \cdot 10^{-3}} \\ {-0,061} & {-0,023} & {0,015} & {0,022} & {0,016} \\ {-0,085} & {-0,052} & {-1,636 \cdot 10^{-3}} & {0,016} & {0,064}\end{array}\right]](https://cmi.to/wp-content/ql-cache/quicklatex.com-d6d0052357c4831ad77b9fd8004a9a8a_l3.png "Rendered by QuickLaTeX.com")
Решая в соответствии с (1.8) уравнение пятой степени относительно λ1

находим собственные значения λ1 = 0,463; λ2 = 0,047; λ3 = 0,038; λ4 = = 2,7 • 10–3; λ5 = 8,1*10 –4. Они упорядочены в порядке убывания их значений.
Подставляя последовательно численные значения λ1, λ2, λ3, λ4, λ5 в систему уравнений (1.7) и решая ее относительно неизвестных Li = [ li1 li2 li3 li4 li5]T, i = 1, 2, 3, 4, 5, находим
![\left.\mathbf{L}_{1}=\left[\begin{array}{c}{-0,835} \\ {-0,469} \\ {-0,015} \\ {0,148} \\ {0,246}\end{array}\right], \left. \mathbf{L}_{2}=\left[\begin{array}{c}{-0,228} \\ {0,431} \\ {0,724} \\ {0,453} \\ {0,182}\end{array}\right], \left.\mathbf{L}_{3}=\left[\begin{array}{c}{0,217} \\ {0,132} \\ {0,172} \\ {0,089} \\ {0,947}\end{array}\right], \left.\mathbf{L}_{4}=\left[\begin{array}{c}{0,421} \\ {-0,575} \\ {0,018} \\ {0,696} \\ {-0,085}\end{array}\right], \left.\mathbf{L}_{5}=\left[\begin{array}{c}{0,162} \\ {-0,469} \\ {0,667} \\ {-0,53} \\ {-0,039}\end{array}\right]](https://cmi.to/wp-content/ql-cache/quicklatex.com-5684db9592c0a90108e728267cddac3a_l3.png "Rendered by QuickLaTeX.com")
В качестве главных компонент получаем
y(1) = -0,84x(1) – 0,47x(2) – 0,02x(3) + 0,15x(4) + 0,25x(5),
y(2) = -0,23x(1) +0,43x(2) + 0,72x(3) + 0,45x(4) – 0,18x(5),
y(3) = 0,22x(1) + 0,13x(2) + 0,17x(3) + 0,09x(4) + 0,95x(5),
y(4) = 0,42x(1) – 0,57x(2) = 0,02x(3) + 0,70x(4) – 0,08x(5),
y(5) = 0,16x(1) – 0,47x(2) + 0,67x(3) – 0,53x(4) – 0,04x(5).
Здесь под x(1), x(2), x(3), x(4), x(5) подразумеваются отклонения параметров энтропии от их средних значений.
Вычисление относительной доли суммарной дисперсии, обусловленной пятью главными компонентами, в соответствии с формулой (1.9) дает следующие результаты:





По результатам вычислений можно сделать вывод о том, что почти вся информация (92,5 %) об изменчивости энтропийных характеристик наблюдаемой выборки ЭКГ-данных (75 объектов) содержится в первых двух главных компонентах.
Па рис.2 приведено изображение множества ритмограмм в пространстве двух первых главных компонент для трех классов ЭКГ (МЛ, HP, ЧЭ).
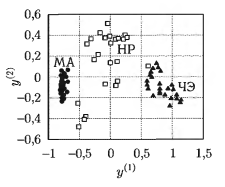
Как видно из рисунка, описание объектов параметрами энтропии позволяет получить группировку объектов, соответствующую трем классам рассматриваемых ЭКГ-сигналов. Наиболее плотная группировка объектов наблюдается в классе МЛ. Возможно линейное разделение классов, причем, используя энтропийные характеристики ритмограмм, можно эффективно решить задачу распознавания опасного нарушения (МА) на фоне альтернативных групп аритмий (ЧЭ и HP с выраженной дыхательной аритмией).
Метод главных компонент для удаления шума
Метод главных компонент находит применение при компрессии изображений и видео для уменьшения пространственной избыточности пикселей при кодировании изображений и видео, когда используются линейные преобразования блоков пикселей. Также метод используется и при обработке биомедицинских сигналов, таких как ЭЭГ.
Метод главных компонент решает следующие задачи:
- Очищение сигнала от шумов.
- Локализация основных частот сигнала
При удалении шума из сигнала необходимо представить данные в многомерном пространстве, применить к нему метод главных компонент и оставить только первые компоненты преобразования. При этом предполагается, что в первых компонентах содержится основная полезная информация, оставшиеся же компоненты содержат ненужный шум.
Преимущество данного метода состоит в том, что метод не требует от пользователя заданную точность. Целевой подход к оценке числа главных компонент по необходимой доле объяснённой дисперсии формально применим всегда. Однако, где нет разделения на «сигнал» и «шум» любая заранее заданная точность имеет смысл. Таким образом, «сигнал» предполагает сравнительно малую размерность при относительно большой амплитуде. «Шум» предполагает большую размерность при относительно малой амплитуде. С этой точки зрения метод главных компонент работает как фильтр: сигнал содержится в основном в проекции на первые главные компоненты, а в остальных компонентах пропорция шума намного выше.