Медицинская диагностика на основе логических систем
При попытке автоматизации диагностического процесса возникает необходимость использовать знания, накопленные врачами. В большинстве случаев эти знания выражены детерминировано (без привлечения вероятностных категорий) в виде логических категорий, что приводит к алгоритмическому представлению диагностического процесса. Такие диагностические алгоритмы могут быть описаны разными способами. К наиболее часто используемым описаниям алгоритмов относятся формулы алгебры логики, блок-схемы, деревья решений, таблицы решений и список последовательно выполняемых команд. Все эти представления алгоритмов эквивалентны, поэтому из любого описания алгоритма можно получить любое другое.
Для описания диагностической процедуры часто используют метод таблиц решений (ТР). Эти таблицы являются идеальными структурами для описания многочисленных решающих правил. Основная структура ТР (табл. 1.4) включает матрицу условий, состоящую из знаков Д (Да), 11 (Нет) и «—» (Безразлично), и матрицу действий, состоящую из знаков х и «-». Знаки матрицы условий соответствуют ограничениям на условия, формируемые слева в этой же строке, а матрица действий с помощью знака х указывает какое (или какие) действия надлежит выполнять, если выполнены все условия (с учетом сформулированных ограничений) данного правила.
Таблица 1
| Наименование таблицы | Правило 1 | Правило 2 | … | Правило М | |
| ЕСЛИ | Условие 1 | ||||
| и | Условие 2 | ||||
| и | …. | ||||
| и | Условие | ||||
| ТОГДА | Действие 1 | ||||
| и | Действие 2 | ||||
| и | ….. | ||||
| и | Действие К | ||||
Например, если вектор-столбец какого-либо правила имеет вид
| L | — | H | — | х | х |
то это правило формулируется так: «Если выполняется условие 1 и не выполняется условие 3, то нужно выполнить действие 2, а затем действие 3».
Проверка правил может происходить независимо, а может иметь последовательный характер: правило 1, правило 2 и т.д. При последовательном характере выполнения правил, если ни одно условие данного правила не выполняется, переходят к следующему правилу, и так далее, пока не будет найдено первое выполняющееся правило. Тогда проверка правил заканчивается и переходят к выполнению действий, соответствующих этому выполняющемуся правилу.
Примерами таблиц решений (с последовательным характером проверки правил), применяющихся в системе автоматической интерпретации ЭКГ, являются табл. 2 и 31.
Таблица 2
| ЭКГ-диагностика | Гипертрофия желудочков (ГЖ), часть I | Номер правила | ||||
| 1 | 2 | 3 | 4 | Иначе | ||
| Синдром WPW (WPW) | Н | Н | Н | — | — | |
| Блокада правой ножки пучка Гиса (RBBB) | Н | Н | — | — | — | |
| Возраст 40 лет | Д | — | — | — | — | |
| RDv1 > 40 мс | Д | — | — | — | — | |
| Отклонение оси QRS влево на 80 | Д | — | — | — | — | |
| RA/SAv1 > 1,0 | Д | — | — | — | ||
| Блокада левой ножки пучка Гиса (LBBB) | — | — | Н | Д | — | |
| (Возможно) гипертрофия правого желудочка или перенесенный инфаркт | X | — | — | — | — | |
| Перейти к таблице ГЖ, часть II | — | X | — | — | — | |
| Перейти к таблице ГЖ, часть III | X | — | — | — | — | |
| Перейти к таблице ГЖ, часть IV | — | — | X | — | — | |
| Перейти к таблице ГЖ, часть V | — | — | — | X | — | |
| Перейти к таблице ГЖ, часть VI | — | — | — | — | X | |
Таблица 3
| ЭКГ-диагностика | Гипертрофия желудочков (ГЖ), часть II | Номер правила | |||||
| 1 | 2 | 3 | 4 | 5 | Иначе | ||
| Возраст > 16 лет | Д | Д | Д | Д | Д | – | |
| RA/SAv1 > 1,0 | Д | – | – | – | – | – | |
| RA/SA’l > 1,0 | – | Д | – | – | – | – | |
| Отклонение оси вправо > 110° | – | – | Д | – | – | – | |
| Отклонение оси влево > -31° | – | – | – | Н | Н | – | |
| RA/SAv5> 1,0 | – | – | – | Д | – | – | |
| RA/SAv6> 1,0 | – | – | – | – | Д | – | |
| (Возможно) гипертрофия правого желудочка | X | X | X | X | X | – | |
| Перейти к таблице ГЖ. часть III | X | X | X | X | X | X | |
Они являются частью решающих правил для диагностики гипертрофии желудочков, которая, в свою очередь, является частью процедуры контурного анализа ЭКГ. Входом в программу контурного анализа ЭКГ являются выходные данные программ распознавания зубцов и анализа аритмий, Р-зубца и электрической оси сердца. Данные о наличии синдрома WPW и блокады ножек пучка Гиса (RBBB и LBBB) получают на предыдущих этапах контурного анализа. Допустим, что на данном этапе анализа данные о пациенте имеют вид
WPW……………………Нет
RBBB……………………Нет
Возраст ≥ 40 лет……………..Да
RDv1 ≥40 мс………………Нет
Отклонение оси QRS влево на 80°. . . Нет
RA/SAvl > 1……………….Нет
I.ВВВ……………………Нет,
где индекс v1 означает, что параметры RA, RD и SA получены в отведении v1. Непосредственной проверкой можно установить, что полученный вектор данных пациента (Н, Н, Д, Н, Н, Н, Н) не удовлетворяет правилу 1, но удовлетворяет правилу 2 таблицы ГЖ. часть I (табл. 2). Согласно этому правилу осуществляется переход к таблице решений ГЖ, часть II (табл. 3). Для этой второй таблицы строится свой вектор данных. Пусть он равен (Д, Н, Н, Н, Н, Д, Н). Тогда он удовлетворяет правилу 4, что вызывает печать сообщения «(Возможно) гипертрофия правого желудочка» и переход к таблице решении ГЖ, часть III, и т.д. В момент окончания всей программы печатается сообщение «Интерпретация должна быть проведена кардиологом».
Теория таблиц решений
Рассмотрим таблицы с простыми (ограниченными) входами, условия которых являются булевыми функциями с двумя значениями: «истина» и «ложь». Эти значения обозначаются в теле условия соответственно как Д (Да) и Н (Нет). Будем считать, что проверка правил может производиться в произвольной последовательности. Для таких таблиц число возможных исходов (число правил) равно 2П, где п — число условий. Например, для трех условий (Cl, С2, СЗ) число правил равно 23 — 8, и матрица условий будет иметь вид

Под матрицей условий изображены действия (диагнозы), соответствующие столбцу условий. Данная таблица может быть также представлена следующими восемью уравнениями алгебры логики:
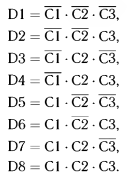
Таблица решений с n условиями называется формально полной, если для каждой из всех 2n ситуаций предусмотрено по одному решающему правилу, поэтому вышеприведенная таблица является полной.
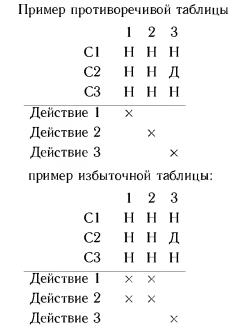
Таблица решений может оказаться двусмысленной. В случае, когда одновременно могут удовлетворяться 2 правила или более, приводящие к различным действиям, таблица называется противоречивой. Если же одновременно удовлетворяются 2 или более правила, но они ведут к одним и тем же действиям, то такая таблица называется избыточной. Пример противоречивой и избыточной таблиц приведен ниже.
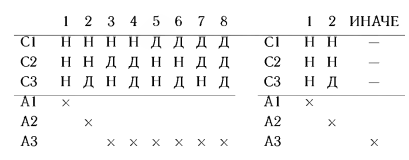
Так как даже при небольших n число правил может оказаться значительным, для сокращения записи таблиц применяют методы сокращения их описания. Первый метод заключается в применении символа «—» для обозначения того, что значение данного условия несущественно для данного правила. Например, ниже слева изображены два столбца таблицы решений:

Видно, что состояние условия СЗ не играет роли, так как в обоих случаях будут выполнены действия A2 и A4. Используя тирс, можно слить эти два столбца в один, как показано справа.
В таблице решений с ограниченным входом каждое тире означает замену двух правил решений на одно. Если в правиле решений записано n тире, то таким одним правилом решений заменено правил решений, не содержащих тире. Таким образом, использование тире нс мешает проверке полноты. Ниже представлены примеры проверки полноты.

Второй метод сокращения заключается в использовании правила ИНАЧЕ. Ниже приведен пример использования этого правила. Правила 3-8 ведут к одному и тому же действию AЗ и поэтому могут быть заменены одним правилом ИНАЧЕ. Таблица решений, использующая его, по определению полна, так как явно или неявно (в правиле ИНАЧЕ) в ней выражено любое возможное правило.
Третий часто применяемый способ сокращения ТР — это использование последовательного характера проверок правил. В таких таблицах проверки правил осуществляются последовательно, а переход к проверке следующего правила происходит, только если данное правило не удовлетворяется.
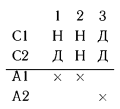
Рассмотрим простой пример. Дана следующая ТР:

Если в этой таблице рассмотреть произвольную последовательность проверки правил и перейти от нее к формально полной ТР, то получим таблицу.
В ней правила 1 и 3 совпадают, что ведет к неопределенности. Однако если допустить последовательный характер проверки правил, то мы приходим к формулам
A1 =  = • С2 + •
= • С2 + •  ,
,
А2 =  • С2 = С1 • С2,
• С2 = С1 • С2,
которые дают следующую формально полную ТР:
ТР с последовательным характером проверки правил широко используются на практике, в частности для медицинской диагностики. При составлении таких таблиц легко допустить неопределенность или противоречивость. Не останавливаясь на проблемах полноты и непротиворечивости, будем считать, что неопределенных и противоречивых ситуаций у нас нет.
Обработка ТР методом маски
Обработку таблиц решений удобно производить формальными методами. Один из наиболее распространенных — метод маски23, заключается в вычислении по заданной ТР двух двоичных матриц: табличной матрицы Т и матрицы масок Л. Матрица Т получается из матрицы условий ТР заменой символов Д на I и помещения нулей в остальные места. Матрица Л содержит О вместо «—», а в остальных местах — 1. Например, для ТР, приведенной в табл. 1, матрицы Т и Л будут иметь вид табл. 1.
Обработка ТР производится последовательной проверкой возможности применения какого-либо правила к входному вектору С (вектору данных пациента), который является результатом проверки условий данной ТР и кодируется так же, как и табличная матрица Т. В начале обработки первый столбец матрицы Л умножается на вектор-столбец С для приведения к нулю незначимых для первого правила составляющих С, а затем полученный вектор сравнивается с первым столбцом матрицы Т. В случае совпадения совершается переход к соответствующим действиям; при несовпадении второй столбец матрицы Л умножается на С, а результат сравнивается со вторым столбцом матрицы Т, и т.д. Допустим, что для ТР, приведенной в табл. 1, вектор-столбец данных пациента равен С = (0,1,1). Первый же вектор-столбец матрицы
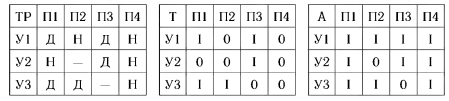
Л равен A1 = (1, 1, 1). В этом случае
А1 • С = (0, 1, 1) ≠ (1, 0, 1) = Т1;
А2 • С = (0, 0, 1) = (0, 0, 1) = Т2,
что означает необходимость использования правила П2.
Переход от ТР к блок-схемам алгоритмов (ТР с независимыми проверками)
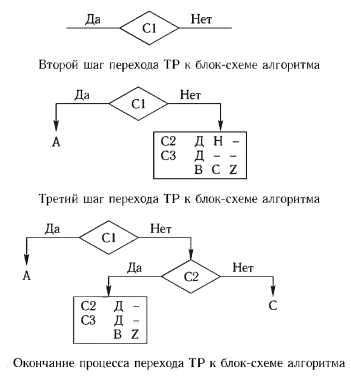
Дана следующая ТР:
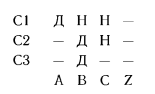
Выбираем произвольно для первой проверки CI (рис. 1).
Если С1 принимает значение Да, то вне зависимости от значений условий 2 и 3 должно быть выполнено действие А. Однако при С1. равном Пет, остается часть ТР, которую надо обрабатывать дальше. Эта стадия преобразований может быть изображена, как на рис. 1.
Теперь в качестве очередной проверки в оставшейся части ТР возьмем условие С2 (рис. 1). Преобразование ТР завершается проверкой условия СЗ в оставшейся части ТР (рис. 2).
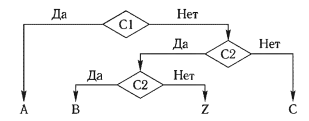
Переход от ТР к блок-схемам алгоритмов (ТР с последовательной проверкой)
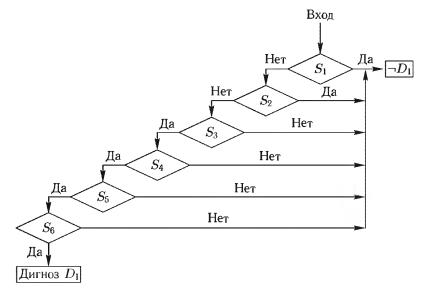
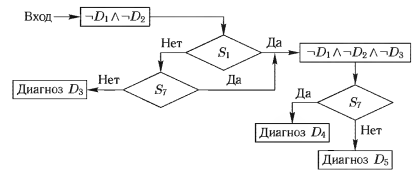
Рассмотрим диагностику 5 заболеваний D1, D2, D3, D4, D5 по 7 признакам (симптомам) S1, S2, S3, S4, S5, S6, S7. Диагностический процесс может быть неформально описан в виде 5 тестов следующим образом.
- Тест 1. Вначале проверяем наличие заболевания D1. Диагноз D1 ставится, если есть признаки S3, S4, S5, S6, и нет признаков S1, S2.
- Тест 2. При отсутствии заболевания D1 проверяем наличие заболевания D2. Диагноз D2 ставится, если нет признаков S1, S2.
- Тест 3. При отсутствии заболеваний D1 и D2 проверяем наличие заболевания D3. Диагноз D3 ставится, если нет признаков S1 и S7.
- Тест 4. При отсутствии заболеваний D1, D2,D3 проверяем наличие заболевания D4. Диагноз D4 ставится, если есть признак S7.
- Тест 5. При отсутствии заболеваний (отрицательных диагнозах) D1, D2, D3, D4 ставится диагноз D5.
Эта диагностическая процедура наглядно изображена в виде таблицы решений (табл. 2).
В столбцах этой таблицы расположены диагностические тесты и их результат. Буква Д означает Да, т.е. наличие соответствующего признака. Буква Н (Нет) означает отсутствие соответствующего признака.
Таблица 2
| Признак | Диагностические тесты | ||||
| 1 | 2 | 3 | 4 | 5 | |
| S1 | H | Н | Н | — | — |
| S2 | Н | Н | — | — | — |
| S3 | Д | — | — | — | — |
| S4 | Д | — | — | — | — |
| S5 | Д | — | — | — | — |
| S6 | Д | — | — | — | — |
| S7 | — | — | Н | Д | — |
| Диагноз | D1 | D2 | D3 | D4 | D5 |
Прочерк (—) означает, что наличие или отсутствие данного признака безразлично. В нижней строке таблицы расположены диагнозы, которые принимаются, если входные данные удовлетворяют условиям соответствующего теста. Тесты применяются строго последовательно слева направо, и процедура останавливается при выдаче первого диагноза. Первый тест (первый столбец) показывает, что если нет (Н) признаков S1 и S2, но есть (Д) признаки S3, S4, S5, S6, то принимается диагноз D1. Второй тест, применяемый при отрицательном результате первого, показывает, что если нет признаков S1, S2, то принимается диагноз D2, и т.д.
Теперь по столбцам таблицы решений можно легко составить формулы алгебры логики, которые описывают диагностику данных заболевании:

Конечно, используя таблицу решений или логические выражения, легко перейти к блок-схеме алгоритма диагностики, однако она будет содержать некоторое число одинаковых проверок (задача минимизации проверок может решаться если перейти от данной ТР к ТР с независимыми проверками). Блок-схема алгоритма диагностики приведена ниже. Первое правило ТР (первый столбец) дает следующую блок-схему (рис. 3).
Второй столбец ТР (второе правило) изображен в виде блок-схемы, приведенной на рис. 4. Третий и четвертый столбцы (третье и четвертое правила) изображены в виде схемы, приведенной на рис. 5. Можно объединить вышеприведенные схемы в блок-схему диагностического алгоритма.

Характеристики точности и цены диагностики
Пусть мы используем бинарный тест для установления факта наличия или отсутствия некоторого заболевания в определенной популяции населения. Пусть А обозначает ситуацию, когда пациент имеет определенную патологию (заболевание), а N — ситуацию, когда пациент не имеет этой патологии (является нормальным). Допустим априорные вероятности Р(А) и P(N), соответственно, обозначают доли в тестовой популяции страдающих данным заболеванием пациентов и нормальных пациентов. Пусть Т+ представляет собой положительный результат теста (наличие заболевания), а Т– — отрицательный результат (отсутствие заболевания). Существуют следующие возможности:
- Истинно положительный результат представляет собой ситуацию, когда тест является положительным для пациента, имеющего заболевание (известный также как правильная диагностика или чувствительность). Этот показатель определяется как Р(Т+ | А) или
S+ = (число положительных результатов теста) / (число субъектов с заболеванием А)
Чувствительность теста отражает его способность обнаруживать присутствие искомого заболевания.
- Истинно отрицательный результат представляет собой случай, когда тест является отрицательным для пациента, который не имеет заболевания. Этот показатель, называемый как специфичность S , задается как Р(Т– | N) или
S– = (число отрицательных результатов теста) / (число субъектов без заболевания)
Специфичность теста показывает точность определения отсутствия исследуемого заболевания.
- Ложно отрицательный результат (пропуск цели) — это ситуация. когда тест является отрицательным для пациента, который имеет исследуемое заболевание; т. е. данный тест пропустил этот случай. Вероятность такой ошибки равна β = Р(Т– | А).
- Ложно положительный результат (ложная тревога) определяется как случай, когда результат теста является положительным, а пациент, который тестируется, не имеет данного заболевания. Вероятность этого типа ошибки равна α = Р(Т+ | N).
В матрице результатов классификации (табл. 1) сведены все возможные результаты классификации.
Отметим, что
Таблица 1
| Истинный диагноз | Предсказанный диагноз | |
| Отсутствие заболевания | Наличие заболевания | |
| Отсутствие заболевания | S– | α = Р(Т+ | N) |
| Наличие заболевания | β = Р(Т– | А) | S+ |
- Р(Т+ | А) + Р(Т– | А) = 1,
- Р(Т+ | N) + P(Т– | N) = I,
- S– = 1 – Р(Т+ | N) = Р(Т– | N), и
- S+ = 1 – Р(Т– | А) = Р(Т+ | А).
Суммарный показатель точности может быть определен как
точность = S+P(A) + S–P(N),
где Р(А) — это доля исследуемой популяции, которая в действительности имеет данное заболевание (распространенность этого заболевания), a P(N) — это доля исследуемой популяции, которая в действительности нс страдает этим заболеванием.
При разработке нового теста или метода диагностики для подтверждения присутствие или отсутствие некоторого заболевания необходимо использовать другой предварительно созданный метод в качестве референтного. Такой референтный метод часто называют золотым стандартом. При испытании метода, основанного на компьютерной обработке, чаще всего в качестве золотого стандарта используют диагностику, которая была выполнена специалистом в данной области. Для этой же цели могут также использоваться хорошо опробованные лабораторные или исследовательские процедуры. Термин «Истинный диагноз» в табл. 2 показывает результат использования золотого стандарта, а термин «Предсказанный диагноз» относится к результату проведенного теста. Может также быть интересной информация о вероятности того, что пациент, у которого результат тестирования оказался положительным, в действительности имеет данное заболевание: эта информация дастся условной вероятностью Р(А | Т+). Па данный вопрос можно ответить с помощью теоремы Байеса, используя которую мы можем получить

Отметим, что Р(Т+ | А) = S+ и Р(Т+ | N) = 1 — S–. Для того чтобы определить значения апостериорной вероятности, необходимо знать чувствительность и специфичность теста, а также априорные вероятности отрицательных и положительных случаев (степень распространенности данного заболевания).
Для того чтобы охарактеризовать общую ценовую эффективность теста или метода диагностики, может быть определена матрица стоимости диагностики (табл. 2).
Таблица 2
| Истинный диагноз | Предсказанный диагноз | |
| Отсутствие заболевания | Наличие заболевания | |
| Отсутствие заболевания | СN | С+ |
| Наличие заболевания | С– | СA |
Стоимость получения истинно отрицательного решения характеризуется величиной СN; эта цена того, что нормальный пациент получит предсказанный диагноз об отсутствии данного заболевания. Стоимость получения истинно положительного решения показывает величина СA: она может включать стоимость дальнейшего лечения, отслеживания и т.д., которые являются вторичными по отношению к самому тесту, но являются частью программы диагностики и поддержки здоровья. Величина С+ показывает стоимость «ложной тревоги»: она представляет собой стоимость того, что пациент, у которого нет заболевания, будет, ошибочно, подвергнут дальнейшей диагностике или терапии. Стоимость С– — это цена «пропуска цели»: присутствовавшее заболевание у пациента не было диагностировано, ситуация ухудшается со временем, пациент сталкивается с дальнейшими трудностями данного заболевания и система здравоохранения или пациент должны нести расходы на дальнейшие тесты и задержанную терапию.
Коэффициент проигрыша, связанный с неправильной классификацией, может быть определен как
Q = α • С+ + β • С–.
Тогда общая стоимость программы скрининга может быть оценена как
Cs = S+ • CA + S– • CN + α • С+ + β • С–.
Рабочие характеристики
Характеристики суммарной правильной диагностики, выраженные в процентах, имеют ограниченные возможности для оценки точности какого-либо диагностического метода. Некоторое улучшение анализа может быть достигнуто за счет использования отдельных оценок правильности диагностики, таких как чувствительность и специфичность для каждой категории. К сожалению, эти характеристики не показывают зависимости результатов диагностики от решающего порога.
Было бы желательно иметь тест для скрининга или диагностики, который одновременно был бы и высокочувствительным, и высокоспецифичным. Однако в реальности такой тест обычно не достижим.
В реальности таким тестам, как правило, свойственен компромисс между чувствительностью и специфичностью. Соотношение между чувствительностью и специфичностью иллюстрируется рабочей характеристикой (ROC-кривой, от англ. receiver operating characteristics, рабочие характеристики пользователя), которая позволяет осуществить более полный анализ точности классификации диагностического метода.
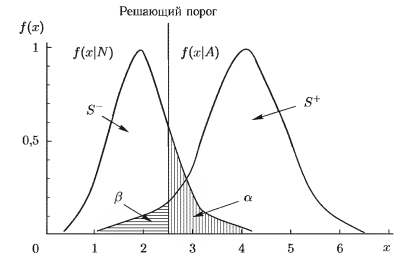
Рассмотрим ситуацию, показанную на рис. 1. Допустим, что для данного диагностического теста с решающей переменной x мы имеем предварительно определенные функции плотности вероятности для нормальных случаев, обозначенную как f(x | N), и для анормальных случаев, обозначенную как f(x | A). Как показано на рис. 1, эти две функции будут почти всегда перекрываться, поскольку ни один из методов не может быть совершенным. Пользователь должен так определить решающий порог (показанный вертикальной линией), чтобы достигнуть компромисса между чувствительностью и специфичностью. Понижение решающего порога будет увеличивать S+ за счет увеличения α. (Замечание: S– и β могут быть легко получены из α и S+, соответственно.)
ROC-кривая — это график, который показывает точки (α, S+). полученные для некоторого диапазона значений решающего порога (см. рис. 2). Меняя решающий порог, мы получаем различные решения в пределах диапазона (0, 1). ROC-кривая описывает свойства обнаружения, присущие какому-либо тесту или методу: пользователь может выбрать для работы любую точку на кривой. ROC-кривая не зависит от распространенности исследуемого заболевания. Так как в принципе возможна ситуация, когда все случаи будут отмечены как отрицательные или, наоборот, как положительные, то ROC-кривая проходит через точки (0, 0) и (1, 1).
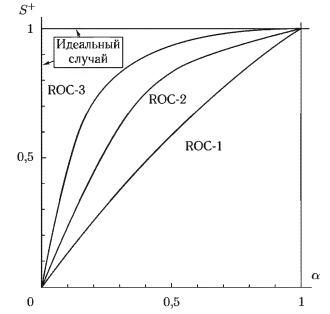
Суммарной характеристикой эффективности теста является площадь под ROC-кривой Sx. Из рис. 2 видно, что величина ограничена диапазоном (0, 1). Тест, который дает большую площадь под ROC-кривой, означает лучший метод, чем тот, который дает меньшую площадь: на рис. 2 метод, соответствующий кривой ROC-3, лучше, чем метод, соответствующий кривой ROC-2; и оба лучше, чем метод, представленный кривой ROC-1, при которой Sx =0,5. Идеальный метод будет иметь ROC-кривую, которая следует по вертикальной линии от точки (0,0) до точки (0, 1) и далее по горизонтальной линии от точки (0, 1) до точки (I, 1), и имеет Sx = 1. Такой идеальный метод имеет S+ = 1 и α = 0. Это требует, чтобы кривые, представленные на рис. 1. не перекрывались.
Footnotes
- Немирно А. П. Микропроцессорные медицинские диагностические системы: учеб, пособие / ЛЭТИ. — Л.» 1984. — 64 с.
- Введение в технику работы с таблицами решений / Пер с нем.; Г. Фрай-таг, В. Годе, X. Якоби и др.; под ред. Д. Л. Поспелова. – М.: Энергия, 1979. – 88 с.
- Хамби Э. Программирование таблиц решений / Пер с англ. М.: Мир, 1976. – 86 с.